下面的表1是一个配对比较量表的例子。

访问结束之后,可以将受测者的回答整理成表格的形式,下面的表2是根据某受访者的回答整理得到的结果。表中每一行列交叉点上元素表示该行的品牌与该列的品牌进行比较的结果,其中元素“1”表示受测者更喜欢这一列的品牌,“0”表示更喜欢这一行的品牌。将各列取值进行加总,得到表中合计栏,这表明各列的品牌比其它品牌更受偏爱的次数。
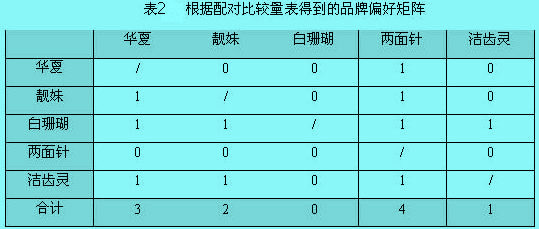
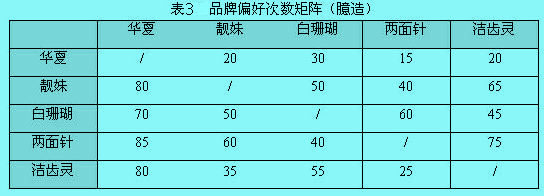
从上表中看到该受测者在华夏牙膏和靓妹牙膏中更偏爱前者(第二行第一列数字为1)。在“可传递性”的假设下,可将配对比较的数据转换成等级顺序。所谓“可传递性”是指,如果一个人喜欢A品牌甚于B品牌,喜欢B品牌甚于C品牌,那么他一定喜欢A品牌甚于C品。将表的各列数字分别加总,计算出每个品牌比其他品牌更受偏爱的次数,就得到该受测者对于5个牙膏品牌的偏好,从最喜欢到最不喜欢,依次是两面针、华夏、靓妹、洁齿灵和白珊瑚。假设调查样本容量为100人,将每个人的回答结果进行汇总,将得到表3的次数矩阵。再将次数矩阵变换成比例矩阵(用次数除以样本数),如表3所示,在品牌自身进行比较时,我们令其比例为0.5。
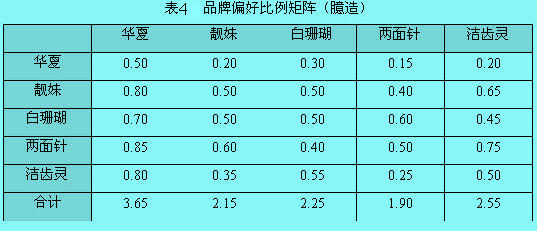
从表4中的合计栏中,可以看出5个品牌中华夏牌牙膏被认为是最好的,洁齿灵次之,再次是白珊瑚和靓妹,两面针最差。但这是一个顺序量表,只能比较各品牌的相对位置,不能认为“华夏牙膏比洁齿灵要好1.1,白珊瑚要比靓妹好0.1”。要想衡量各品牌偏好间的差异程度必须先将其转化为等距量表,这里就不再深入讨论了。
当要评价的对象的个数不多时,配对比较法是有用的。但如果要评价的对象超过10个,这种方法就太麻烦了。另外一个缺点是“可传递性”的假设可能不成立,在实际研究中这种情况常常发生。同时对象列举的顺序可能影响受测者,造成顺序反应误差。而且这种“二中选一”的方式和实际生活中作购买选择的情况也不太相同,受访者可能在A、B两种品牌中对A要略为偏爱些,但实际上却两个品牌都不喜欢。