1.什么是数据清洗[1]
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
- 1.一致性检查
一致性检查(consistency check)是根据每个变量的合理取值范围和相互关系,检查数据是否合乎要求,发现超出正常范围、逻辑上不合理或者相互矛盾的数据。例如,用1-7级量表测量的变量出现了0值,体重出现了负数,都应视为超出正常值域范围。SPSS、SAS、和Excel等计算机软件都能够根据定义的取值范围,自动识别每个超出范围的变量值。具有逻辑上不一致性的答案可能以多种形式出现:例如,许多调查对象说自己开车上班,又报告没有汽车;或者调查对象报告自己是某品牌的重度购买者和使用者,但同时又在熟悉程度量表上给了很低的分值。发现不一致时,要列出问卷序号、记录序号、变量名称、错误类别等,便于进一步核对和纠正。
- 2.无效值和缺失值的处理
由于调查、编码和录入误差,数据中可能存在一些无效值和缺失值,需要给予适当的处理。常用的处理方法有:估算,整例删除,变量删除和成对删除。
估算(estimation)。最简单的办法就是用某个变量的样本均值、中位数或众数代替无效值和缺失值。这种办法简单,但没有充分考虑数据中已有的信息,误差可能较大。另一种办法就是根据调查对象对其他问题的答案,通过变量之间的相关分析或逻辑推论进行估计。例如,某一产品的拥有情况可能与家庭收入有关,可以根据调查对象的家庭收入推算拥有这一产品的可能性。
整例删除(casewise deletion)是剔除含有缺失值的样本。由于很多问卷都可能存在缺失值,这种做法的结果可能导致有效样本量大大减少,无法充分利用已经收集到的数据。因此,只适合关键变量缺失,或者含有无效值或缺失值的样本比重很小的情况。
变量删除(variable deletion)。如果某一变量的无效值和缺失值很多,而且该变量对于所研究的问题不是特别重要,则可以考虑将该变量删除。这种做法减少了供分析用的变量数目,但没有改变样本量。
成对删除(pairwise deletion)是用一个特殊码(通常是9、99、999等)代表无效值和缺失值,同时保留数据集中的全部变量和样本。但是,在具体计算时只采用有完整答案的样本,因而不同的分析因涉及的变量不同,其有效样本量也会有所不同。这是一种保守的处理方法,最大限度地保留了数据集中的可用信息。
采用不同的处理方法可能对分析结果产生影响,尤其是当缺失值的出现并非随机且变量之间明显相关时。因此,在调查中应当尽量避免出现无效值和缺失值,保证数据的完整性。
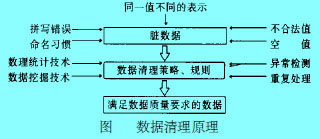
2.数据清洗原理[2]
3.数据清洗的实现方式与范围[2]
按数据清洗的实现方式与范围,可分为4种:
(1) 手工实现,通过人工检查,只要投入足够的人力物力财力,也能发现所有错误,但效率低下。在大数据量的情况下,几乎是不可能的。
(2) 通过专门编写的应用程序,这种方法能解决某个特定的问题,但不够灵活,特别是在清理过程需要反复进行(一般来说,数据清理一遍就达到要求的很少)时,导致程序复杂,清理过程变化时,工作量大。而且这种方法也没有充分利用目前数据库提供的强大数据处理能力 。
(3) 解决某类特定应用域的问题,如根据概率统计学原理查找数值异常的记录,对姓名、地址、邮政编码等进行清理,这是目前研究得较多的领域,也是应用最成功的一类。如商用系统: Trillinm Software , System Match Maketr 等。
(4) 与特定应用领域无关的数据清理,这一部分的研究主要集中在清理重复的记录上,如Data Cleanser Data Blade Module ,Integrity 系统等。
这4种实现方法,由于后两种具有某种通用性,较大的实用性,引起了越来越多的注意。但是不管哪种方法,大致都由三个阶段组成: ①数据分析、定义错误类型; ②搜索、识别错误记录; ③修正错误。
第一阶段,尽管已有一些数据分析工具,但仍以人工分析为主。在错误类型分为两大类:单数据源与多数据源,并将它们又各分为结构级与记录级错误。这种分类非常适合于解决数据仓库中的数据清理问题。
第二阶段,有两种基本的思路用于识别错误:一种是发掘数据中存在的模式,然后利用这些模式清理数据;另一种是基于数据的,根据预定义的清理规则,查找不匹配的记录。后者用得更多。
第三阶段,某些特定领域能够根据发现的错误模式,编制程序或借助于外部标准源文件、数据字典一定程度上修正错误;对数值字段,有时能根据数理统计知识自动修正,但经常须编制复杂的程序或借助于人工干预完成。
绝大部分数据清理方案提供接口用于编制清理程序。它们一般来说包括很多耗时的排序、比较、匹配过程,且这些过程多次重复,用户必须等待较长时间。在一个交互式的数据清理方案。系统将错误检测与清理紧密结合起来,用户能通过直观的图形化界面一步步地指定清理操作,且能立即看到此时的清理结果, (仅仅在所见的数据上进行清理,所以速度很快) 不满意清理效果时还能撤销上一步的操作,最后将所有清理操作编译执行。并且这种方案对清理循环错误非常有效。
许多数据清理工具提供了描述性语言解决用户友好性,降低用户编程复杂度。如ARKTOS 方案提供了XADL 语言(一种基于预定义的DTD 的XML 语言) 、SADL 语言,在ATDX 提供了一套宏操作(来自于SQL 语句及外部函数) ,一种SQL2Like 命令语言,这些描述性语言都在一定程度上减轻了用户的编程难度,但各系统一般不具有互操作性,不能通用。
数据清理属于一个较新的研究领域,直接针对这方面的研究并不多,中文数据清理更少。现在的研究主要为解决两个问题:发现异常、清理重复记录。
4.数据清洗的方法[3]
一般来说,数据清理是将数据库精简以除去重复记录,并使剩余部分转换成标准可接收格式的过程。数据清理标准模型是将数据输入到数据清理处理器,通过一系列步骤“ 清理”数据,然后以期望的格式输出清理过的数据(如上图所示)。数据清理从数据的准确性、完整性、一致性、惟一性、适时性、有效性几个方面来处理数据的丢失值、越界值、不一致代码、重复数据等问题。
数据清理一般针对具体应用,因而难以归纳统一的方法和步骤,但是根据数据不同可以给出相应的数据清理方法。
- 1.解决不完整数据( 即值缺失)的方法
大多数情况下,缺失的值必须手工填入( 即手工清理)。当然,某些缺失值可以从本数据源或其它数据源推导出来,这就可以用平均值、最大值、最小值或更为复杂的概率估计代替缺失的值,从而达到清理的目的。
- 2.错误值的检测及解决方法
用统计分析的方法识别可能的错误值或异常值,如偏差分析、识别不遵守分布或回归方程的值,也可以用简单规则库( 常识性规则、业务特定规则等)检查数据值,或使用不同属性间的约束、外部的数据来检测和清理数据。
- 3.重复记录的检测及消除方法
数据库中属性值相同的记录被认为是重复记录,通过判断记录间的属性值是否相等来检测记录是否相等,相等的记录合并为一条记录(即合并/清除)。合并/清除是消重的基本方法。
- 4.不一致性( 数据源内部及数据源之间)的检测及解决方法
从多数据源集成的数据可能有语义冲突,可定义完整性约束用于检测不一致性,也可通过分析数据发现联系,从而使得数据保持一致。目前开发的数据清理工具大致可分为三类。
数据迁移工具允许指定简单的转换规则,如:将字符串gender替换成sex。sex公司的PrismWarehouse是一个流行的工具,就属于这类。
数据清洗工具使用领域特有的知识( 如,邮政地址)对数据作清洗。它们通常采用语法分析和模糊匹配技术完成对多数据源数据的清理。某些工具可以指明源的“ 相对清洁程度”。工具Integrity和Trillum属于这一类。
数据审计工具可以通过扫描数据发现规律和联系。因此,这类工具可以看作是数据挖掘工具的变形。