1.什么是正态分布
正态分布是一种概率分布。正态分布是具有两个参数μ和σ2的连续型随机变量的分布,第一参数μ是遵从正态分布的随机变量的均值,第二个参数σ2是此随机变量的方差,所以正态分布记作N(μ,σ2 )。遵从正态分布的随机变量的概率规律为取 μ邻近的值的概率大 ,而取离μ越远的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。正态分布的密度函数的特点是:关于μ对称,在μ处达到最大值,在正(负)无穷远处取值为0,在μ±σ处有拐点。它的形状是中间高两边低 ,图像是一条位于x 轴上方的钟形曲线。当μ=0,σ2 =1时,称为标准正态分布,记为N(0,1)。μ维随机向量具有类似的概率规律时,称此随机向量遵从多维正态分布。多元正态分布有很好的性质,例如,多元正态分布的边缘分布仍为正态分布,它经任何线性变换得到的随机向量仍为多维正态分布,特别它的线性组合为一元正态分布。
2.正态分布的发展
正态分布是最重要的一种概率分布。正态分布概念是由德国的数学家和天文学家Moivre于1733年首次提出的,但由于德国数学家Gauss率先将其应用于天文学家研究,故正态分布又叫高斯分布。高斯这项工作对后世的影响极大,他使正态分布同时有了“高斯分布”的名称,后世之所以多将最小二乘法的发明权归之于他,也是出于这一工作。高斯是一个伟大的数学家,重要的贡献不胜枚举。但现今德国10马克的印有高斯头像的钞票,其上还印有正态分布的密度曲线。这传达了一种想法:在高斯的一切科学贡献中,其对人类文明影响最大者,就是这一项。在高斯刚作出这个发现之初,也许人们还只能从其理论的简化上来评价其优越性,其全部影响还不能充分看出来。这要到20世纪正态小样本理论充分发展起来以后。皮埃尔-西蒙·拉普拉斯很快得知高斯的工作,并马上将其与他发现的中心极限定理联系起来,为此,他在即将发表的一篇文章(发表于1810年)上加上了一点补充,指出如若误差可看成许多量的叠加,根据他的中心极限定理,误差理应有高斯分布。这是历史上第一次提到所谓“元误差学说”——误差是由大量的、由种种原因产生的元误差叠加而成。后来到1837年,海根(G.Hagen)在一篇论文中正式提出了这个学说。
其实,他提出的形式有相当大的局限性:海根把误差设想成个数很多的、独立同分布的“元误差” 之和,每只取两值,其概率都是1/2,由此出发,按狄莫佛的中心极限定理,立即就得出误差(近似地)服从正态分布。皮埃尔-西蒙·拉普拉斯所指出的这一点有重大的意义,在于他给误差的正态理论一个更自然合理、更令人信服的解释。因为,高斯的说法有一点循环论证的气味:由于算术平均是优良的,推出误差必须服从正态分布;反过来,由后一结论又推出算术平均及最小二乘估计的优良性,故必须认定这二者之一(算术平均的优良性,误差的正态性) 为出发点。但算术平均到底并没有自行成立的理由,以它作为理论中一个预设的出发点,终觉有其不足之处。拉普拉斯的理把这断裂的一环连接起来,使之成为一个和谐的整体,实有着极重大的意义。
3.正态分布的主要特征
1、集中性:正态曲线的高峰位于正中央,即均数所在的位置。
2、对称性:正态曲线以均数为中心,左右对称,曲线两端永远不与横轴相交。
3、均匀变动性:正态曲线由均数所在处开始,分别向左右两侧逐渐均匀下降。
4、正态分布有两个参数,即均数μ和标准差σ,可记作N(μ,σ):均数μ决定正态曲线的中心位置;标准差σ决定正态曲线的陡峭或扁平程度。σ越小,曲线越陡峭;σ越大,曲线越扁平。
5、u变换:为了便于描述和应用,常将正态变量作数据转换。
4.数据正态分布检验 Q-Q图[1]
要观察某一属性的一组数据是否符合正态分布,可以有两种方法(目前我知道这两种,并且这两种方法只是直观观察,不是定量的正态分布检验):
1:在spss(Statistical Package for the Social Sciences,即“社会科学统计软件包”)里的基本统计分析功能里的频数统计功能里有对某个变量各个观测值的频数直方图中可以选择绘制正态曲线。具体如下:Analyze-----Descriptive Statistics-----Frequencies,打开频数统计对话框,在Statistics里可以选择获得各种描述性的统计量,如:均值、方差、分位数、峰度、标准差等各种描述性统计量。在Charts里可以选择显示的图形类型,其中Histograms选项为柱状图也就是我们说的直方图,同时可以选择是否绘制该组数据的正态曲线(With norma curve),这样我们可以直观观察该组数据是否大致符合正态分布。如下图:
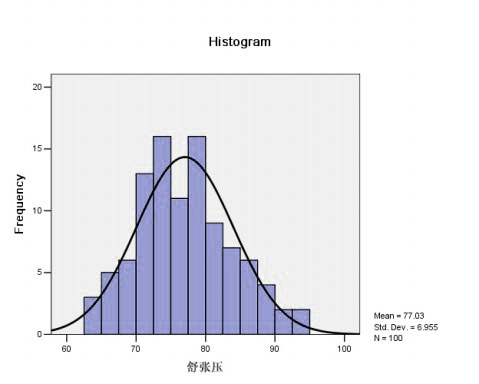
从上图中可以看出,该组数据基本符合正态分布。
2:正态分布的Q-Q图:在spss里的基本统计分析功能里的探索性分析里面可以通过观察数据的q-q图来判断数据是否服从正态分布。
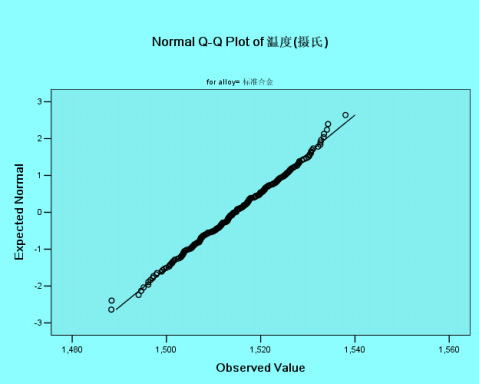
具体步骤如下:Analyze-----Descriptive Statistics-----Explore打开对话框,选择Plots选项,选择Normality plots with tests选项,可以绘制该组数据的q-q图。图的横坐标为改变量的观测值,纵坐标为分位数。若该组数据服从正态分布,则图中的点应该靠近图中直线。
纵坐标为分位数,是根据分布函数公式F(x)=i/n+1得出的.i为把一组数从小到大排序后第i个数据的位置,n为样本容量。若该数组服从正态分布则其q-q图应该与理论的q-q图(也就是图中的直线)基本符合。对于理论的标准正态分布,其q-q图为y=x直线。非标准正态分布的斜率为样本标准差,截距为样本均值。
如下图:
5.正态分布的应用
1.估计正态分布资料的频数分布
例1.某地1993年抽样调查了100名18岁男大学生身高(cm),其均数=172.70cm,标准差s=4.01cm,
①估计该地18岁男大学生身高在168cm以下者占该地18岁男大学生总数的百分数;
②分别求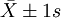 、
、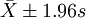 、
、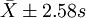 范围内18岁男大学生占该地18岁男大学生总数的实际百分数,并与理论百分数比较。
范围内18岁男大学生占该地18岁男大学生总数的实际百分数,并与理论百分数比较。
本例,μ、σ未知但样本含量n较大,按式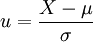 用样本均数
用样本均数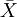 和标准差S分别代替μ和σ,求得u值,u=(168-172.70)/4.01=-1.17。查附表标准正态曲线下的面积,在表的左侧找到-1.1,表的上方找到0.07,两者相交处为0.1210=12.10%。该地18岁男大学生身高在168cm以下者,约占总数12.10%。其它计算结果见表-1。
和标准差S分别代替μ和σ,求得u值,u=(168-172.70)/4.01=-1.17。查附表标准正态曲线下的面积,在表的左侧找到-1.1,表的上方找到0.07,两者相交处为0.1210=12.10%。该地18岁男大学生身高在168cm以下者,约占总数12.10%。其它计算结果见表-1。
表-1:1100名18岁男大学生身高的实际分布与理论分布

2.制定医学参考值范围:亦称医学正常值范围。
它是指所谓“正常人”的解剖、生理、生化等指标的波动范围。制定正常值范围时,首先要确定一批样本含量足够大的 “正常人”,所谓“正常人”不是指“健康人”,而是指排除了影响所研究指标的疾病和有关因素的同质人群;其次需根据研究目的和使用要求选定适当的百分界值,如80%,90%,95%和99%,常用95%;根据指标的实际用途确定单侧或双侧界值,如白细胞计数过高过低皆属不正常须确定双侧界值,又如肝功中转氨酶过高属不正常须确定单侧上界,肺活量过低属不正常须确定单侧下界。另外,还要根据资料的分布特点,选用恰当的计算方法。常用方法有:
(1)正态分布法:适用于正态或近似正态分布的资料。
双侧界值: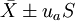 单侧上界:
单侧上界: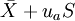 ,或单侧下界:
,或单侧下界: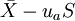
(2)对数正态分布法:适用于对数正态分布资料。
双侧界值: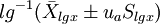 ;单侧上界:
;单侧上界: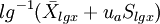 ,或单侧下界:
,或单侧下界: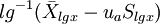 。
。
常用u值可根据要求由表-2查出。
(3)百分位数法:常用于偏态分布资料以及资料中一端或两端无确切数值的资料。
双侧界值:P2.5和P97.5;单侧上界:P95,或单侧下界:P5。
表-2:常用u值表
| 参考值范围(%) | 单侧 | 双侧 |
| 80 | 0.842 | 1.282 |
| 90 | 1.282 | 1.645 |
| 95 | 1.645 | 1.960 |
| 99 | 2.326 | 2.576 |
3.正态分布是许多统计方法的理论基础:如t分布、F分布、x2分布都是在正态分布的基础上推导出来的,u检验也是以正态分布为基础的。此外,t分布、二项分布、Poisson分布的极限为正态分布,在一定条件下,可以按正态分布原理来处理。